



Executive Summary: A business entity verification API for high volume lenders is not the same product category as a verification API for a small monoline lender, even when the marketing pages look identical. At 50,000-plus monthly verifications, the procurement decision stops being about per-call price and starts being about SLA architecture, multi-region failover posture, vendor consolidation strategy, and the executive engineering metrics the CTO has to defend at the board. This guide walks through what high-volume lenders actually demand from the verification layer, what changes when the vendor decision is made at the CTO level rather than the platform-engineer level, and what Cobalt's positioning looks like inside that decision framework.
What Should a Business Entity Verification API for High Volume Lenders Actually Do?
High volume in this category means 50,000-plus monthly business entity verifications, with peak burst loads 3 to 5x the steady state, across all 50 state Secretary of State sources plus OFAC, UCC, and TIN. At that scale, the verification layer is not a vendor integration; it is a load-bearing piece of the lending platform whose downtime is reported on the executive scorecard. Five capabilities determine whether a vendor is operationally ready for that role:
• Documented availability SLA with credit terms, not aspirational language. 99.9 percent or better at the verification layer; 99.5 percent or better acceptable for the long-tail state sources, with documented async behavior.
• Multi-region failover for the vendor's own infrastructure, with documented RTO and RPO targets the vendor will commit to in writing.
• Per-source isolation so a single state source outage does not degrade the rest of the chain. Bulkhead pattern, not shared worker pool.
• Audit-grade artifact stream with primary-source URLs, fetch timestamps, and stable screenshot references on every record, retained per the consumer's compliance requirements.[2]
• Volume-tier contract terms that absorb 3x burst without renegotiation and provide documented pricing for 50K, 100K, and 250K monthly tiers without surprise overage fees.
Vendors that hit four of five are short list. Vendors that hit fewer should not survive a CTO-level procurement gate at this volume.
Why High Volume Changes the Vendor Decision-Maker
At small-shop volume (under 5,000 monthly calls), the verification API decision is a procurement decision and the operations leader signs the contract. At high volume, the decision is an engineering-architecture decision and the CTO or VP Engineering signs the contract because the verification layer is now part of the platform's resiliency story. The buying conversation is materially different: SLA, failover, observability, and integration depth instead of unit cost and feature checklist.[11]
Why Per-Call Price Stops Being the Primary Metric
At 50,000-plus monthly calls, the unit-cost spread between vendors compresses (most vendors land in the $0.10 to $0.30 range at that tier) while the SLA, integration, and failover differences widen materially. CTOs that optimize the contract on per-call price end up renegotiating in 6 to 9 months when the SLA gaps surface. The right ranking criteria at this volume are availability, latency at p99 not p95, and integration debt to maintain.
What SLA and Vendor Performance Patterns Matter at High Volume?
SLA at this layer has to cover three different commitments because the verification chain has three different failure surfaces: the vendor's own infrastructure, the underlying state sources, and the integration plane between them. CTOs who sign a single-line "99.9 percent availability" SLA without breaking out the three layers are signing themselves up for a contract dispute the first time Oregon goes down for two hours.
| SLA layer | What it covers | Reasonable target at high volume |
|---|---|---|
| Vendor infrastructure | API gateway, queue layer, vendor's own data plane | 99.95 percent monthly availability with credit clawback for breaches |
| Per-source synchronous lookup | Live response from vendor for fast-tier states | p95 under 1.5 seconds, p99 under 3 seconds, 99.5 percent success rate |
| Per-source async callback | Webhook fires for slow-tier states | Callback fires within published expectedSeconds value 99 percent of time |
| Aggregate audit-artifact completeness | Source URL plus timestamp plus screenshot per record | 99.9 percent completeness on completed lookups |
| State-source pass-through | The state's own uptime; vendor cannot guarantee but should monitor and surface | Public dashboard showing per-state uptime; documented fallback (queued retry, manual review hold) for state outages |
The state-source layer is where most vendor SLA conversations break down. Reputable vendors do not commit to state-source uptime because they do not control it, but they do commit to the visibility (public dashboard, status page) and the fallback (queued retry, manual review hold) that lets the consumer's CTO build their own SLA on top.[8]
What "p99" Hides That "p95" Reveals
Most vendor decks lead with median or p95 latency. At high volume, p99 is the operationally relevant number because the 1 percent tail is hundreds of files per day at 50K monthly volume. A vendor with p95 of 800ms and p99 of 8 seconds has a real problem; a vendor with p95 of 1.2s and p99 of 2 seconds has a tighter, more predictable distribution. Demand p99 numbers in the SLA conversation; they tell more about the architecture than p95 does.
The SLA Math the Vendor Will Push Back On
Two SLA terms get pushback. First, the credit clawback: vendors prefer "service credits" capped at the monthly fee; CTOs should push for clawback as a percentage of the breach window's revenue impact. Second, the failover RTO: vendors prefer "best effort"; CTOs should push for documented RTO under 15 minutes for vendor-side failures and a credit-clawback trigger if RTO is breached. Both terms are negotiable at high volume; both are non-negotiable at low volume.
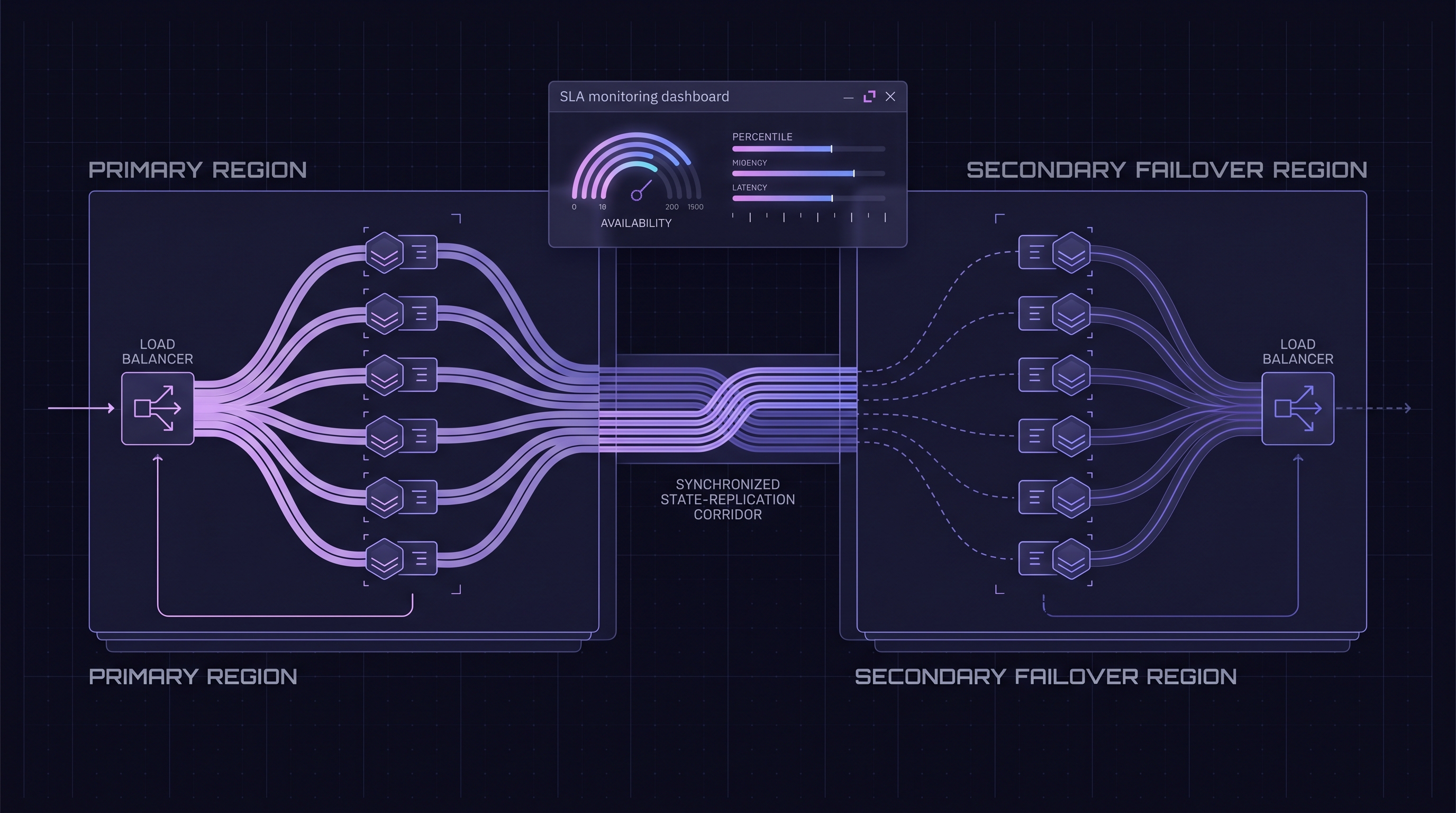
How Should High-Volume Lenders Architect for Vendor Outage?
A vendor with a 99.95 percent SLA still has 22 minutes of permitted downtime per month. At 50,000 monthly verifications, that is roughly 25 to 50 lookups affected during the worst-case outage window. High-volume lenders that depend on real-time verification at the moment of funding cannot absorb that without an outage strategy.
The Three Architectural Patterns
• Queue-and-defer. When the vendor is unreachable, the consumer's loan-management system queues the verification request and returns a "pending" status to the underwriter. The underwriter sees the file with a flagged verification status; the queue retries on vendor recovery. Acceptable for batch workflows; problematic for same-day-funding workflows.
• Manual-review hold. When the vendor is unreachable for more than a documented window (5-10 minutes), the verification leg is routed to a manual review queue with full application context preserved. The verification team handles the file directly against state sources. Adds operational cost during outages; preserves same-day funding capability.
• Multi-vendor failover. Two verification vendors integrated, primary plus secondary; on primary outage, the consumer's API gateway routes to secondary. Most expensive option, highest resiliency, most integration overhead. Only justified at extreme scale (250K+ monthly verifications) or extreme uptime sensitivity (real-time payments rather than lending).
Why Most High-Volume Lenders Land on Pattern Two
The honest pattern across MCA funders, equipment finance lenders, and B2B credit teams at the 50K-150K monthly volume tier: queue-and-defer for the slow async-only states, manual-review hold for vendor outages exceeding the documented window. Multi-vendor failover gets discussed in board strategy meetings and rarely makes it into production architecture because the integration overhead and contract complexity exceed the realized resiliency benefit at most volume tiers.[10]
The Disaster Recovery Conversation Most CTOs Skip
What happens to in-flight verifications when the vendor's primary region fails? The answer should be in the contract: documented RTO, documented RPO, queue persistence, idempotency-key continuity. Vendors that handwave this answer at the procurement stage will handwave it during an actual incident. Demand the runbook, not the marketing language.
What Does the Cost Curve Look Like at 50K+ Monthly Verifications?
The cost curve compresses sharply at high volume. Honest ranges across the lanes at the 50K-plus tier:
• Primary-source data layer: $0.10 to $0.30 per lookup at 50K-plus volumes; paid-jurisdiction passthroughs (Delaware, paid UCC states) usually billed separately as state filing fees change without notice.[6]
• KYB orchestration platform: $0.40 to $1.50 per verified entity at high volume, depending on which upstream sources and which workflow features are bundled.
• Business credit bureau: $1 to $5 per scored report at high volume; depth of report drives the spread.
The strategic cost question at high volume is not "what does each call cost?" but "what is the all-in monthly verification cost as a percentage of monthly originations volume?" At well-run high-volume shops, that ratio lands around 0.05 to 0.15 percent of originations. CTOs benchmarking against that ratio learn quickly whether their stack is cost-competitive.
Where the Hidden Cost Lives at High Volume
Three line items consistently exceed the projected unit cost at the 50K-plus tier. First, paid-jurisdiction passthroughs, especially Delaware, can add 15 to 25 percent to the headline per-call price depending on application mix. Second, async-callback infrastructure on the consumer side (webhook handler, idempotency persistence, queue reconciliation) adds engineering hours that procurement does not budget. Third, multi-vendor SLA monitoring for shops running primary-plus-secondary vendor strategies doubles the integration surface and the on-call rotation.
The Procurement Move That Actually Saves Money
Consolidating from three vendors to one primary plus one fallback typically saves 20 to 30 percent at the 50K-plus tier, primarily because volume commitment unlocks tier pricing and reduces integration debt. CTOs that resist the consolidation move because of imagined resiliency benefits often discover the multi-vendor cost overhead exceeded the resiliency value at audit time.
Should High-Volume Lenders Run a Single-Vendor or Multi-Vendor Strategy?
The single-versus-multi-vendor question divides high-volume lenders. The honest answer is "primary plus fallback for the verification layer specifically, with the rest of the stack consolidated where possible." Strict single-vendor strategies break under outages; strict multi-vendor strategies absorb engineering hours that should ship product. The middle path is the production default.
What Each Strategy Actually Costs in Engineering Hours
| Strategy | Engineering integration hours | On-call burden | Resiliency posture |
|---|---|---|---|
| Single vendor | 1 vendor SDK; 4-6 weeks integration | Single vendor on the runbook | SLA-bounded; no failover beyond vendor's own |
| Primary plus fallback (recommended) | 2 vendor SDKs; 8-12 weeks integration plus failover orchestration layer | Two vendors on runbook; documented routing decision | Vendor-outage tolerant; SLA-bounded |
| Strict multi-vendor (active-active) | 2-3 vendor SDKs; 16-24 weeks integration plus active-active orchestration | Multiple vendors plus reconciliation runbook | Highest resiliency; highest engineering cost |
Where Single-Vendor Wins
Single-vendor wins for shops in the 5,000-25,000 monthly volume tier where the engineering hours saved outweigh the marginal resiliency benefit. It also wins when the vendor's SLA architecture (multi-region, documented RTO, audit-grade artifact stream) is itself the resiliency story, which removes most of the value of a secondary vendor.[7]
Where Primary-Plus-Fallback Wins
Primary-plus-fallback wins at the 50K-plus tier where the cost of a multi-hour vendor outage exceeds the engineering cost of maintaining a fallback integration. The fallback does not need to be active-active; it is on standby with monitored health checks, activated only when the primary breaches SLA.
Related guides on Cobalt's verification stack: How to Automate Secretary of State Business Lookups at Scale, Best Business Data APIs for U.S. Company Verification, and Best Fintech Companies for Real-Time KYB Business Verification.
How Do You Engineer Verification for Same-Day Funding at Scale?
Same-day funding is the deal-velocity story executive leadership cares about, and the verification layer is the most common bottleneck preventing it. At high volume, three engineering decisions determine whether same-day funding actually works:
• Verification fires at submission, not at underwriter pickup. Running the chain on submit means the verification packet is ready when the underwriter picks up the file; running on pickup defeats the parallelization win and adds queue-day latency.
• Async-first contract design. The system always returns a workflowId at submission; for fast states the result is in the same response, for slow states it fires via webhook. A consumer that always treats the response as async simplifies code and absorbs slow-state behavior.
• Edge-case escalation runs in parallel, not serially. When the verification chain flags an edge case, the loan-management system routes it to manual review while continuing to process the rest of the application. Serial escalation kills the same-day funding rate; parallel escalation preserves it.
Where Same-Day Funding Breaks at High Volume
Three failure modes consistently kill same-day funding at the 50K-plus tier. First, synchronous verification calls inside the application's request thread (not a queue) cause the loan-onboarding endpoint to time out under slow-state pressure. Second, single-shared worker pool architectures starve the fast-state requests when slow-state requests pile up; per-source pools prevent this. Third, edge-case escalation paths that require analyst sign-off before the loan can move through underwriting create queue-day delays the customer experiences as "funding tomorrow" rather than "funding today."
The Same-Day-Funding Engineering Metric That Matters
Track the percentage of submitted applications that reach an approval decision within 6 hours of submission, not within "the same business day." The 6-hour metric exposes verification-layer drag that the 24-hour metric hides. Well-run high-volume lenders run the 6-hour metric weekly and surface it on the executive engineering dashboard.[1]
What Compliance Posture Do High-Volume Lenders Need at the Verification Layer?
Compliance at the verification layer scales differently than compliance at the application layer. At low volume, compliance reviews each verification record manually. At high volume (50K-plus monthly), compliance reviews the artifact stream on a sample basis and trusts the structural integrity of the API output. That trust is earned by three properties.
The Three Compliance Properties That Survive at High Volume
• Structural artifact integrity. Every record carries source URL, fetch timestamp, normalized status, and stable screenshot reference. Compliance does not need to review individual records; they need to verify the structural integrity of the field set across the whole stream.[5]
• Per-tier sampling. Compliance samples records by risk tier (high-risk applications, edge-case escalations, common-name collisions) rather than uniformly. Sampling design is the compliance team's contribution; the API's job is to make sampling possible by exposing the metadata that drives tier classification.
• Audit-export performance. The compliance team can pull a complete audit packet for any single verification record in under 5 minutes, including all sub-leg artifacts. Performance below that threshold means audit prep absorbs compliance hours that should be spent on supervisory review.
How OFAC and BOI Specifically Scale at High Volume
OFAC screening on entity name automates cleanly at high volume; OFAC against verified beneficial owners requires a defensible adjudication process for partial matches that most teams keep semi-manual.[3] BOI verification has been through court challenges and is operating under a voluntary-filing posture for domestic reporting companies as of early 2026; the high-volume engineering pattern is to capture-and-store BOI data with manual final review until enforcement posture stabilizes.[9]
What the Bank-Partner Third-Party-Risk File Looks Like at High Volume
Bank-partner third-party-risk reviews at high-volume lenders specifically probe the structural integrity of the verification artifact stream rather than individual records. The CTO contribution to that review is the documented architecture: SLA, failover, audit retention, OFAC adjudication runbook, BOI capture pattern, and edge-case escalation flow. Most of these documents already exist if the engineering team is running the verification layer well; assembling them for the bank partner is a one-week task, not a one-quarter project.
What Should a CTO Actually Demand from a High-Volume Verification Vendor?
The five demands that separate a vendor that survives the CTO procurement gate from a vendor that survives the operations procurement gate:
1. Written SLA with credit clawback for breach, covering vendor infrastructure, per-source latency, and audit-artifact completeness as separate commitments.
2. Documented multi-region failover with RTO and RPO targets, plus an actual incident-response runbook, not marketing language.
3. Per-tier latency commitments at p99 not p95, broken out by state tier so the long-tail states cannot hide behind aggregate metrics.
4. Public state-source status dashboard showing per-state uptime so the consumer's CTO can build their own SLA on top of the vendor's coverage.
5. Volume-tier contract terms documented for 50K, 100K, and 250K monthly tiers with no surprise overage fees and absorbable 3x burst capacity within the contracted price.
Vendors that answer all five without escalating to a sales engineer are short list. Vendors that ask for a follow-up call usually have something to defend.
Where Cobalt Sits in the High-Volume CTO Procurement Decision
Cobalt Intelligence is the primary-source data layer for high-volume lenders running the verification layer at 50K-plus monthly volume. The procurement positioning is honest: Cobalt is the data API the orchestration platform consumes, not the orchestration platform itself. CTOs running primary-plus-fallback strategies typically pair Cobalt as the primary with one of the orchestration platforms (Middesk, Alloy) on top, plus a documented manual-review-hold pattern for vendor outages exceeding the SLA window. Single-vendor strategies that select Cobalt as the sole verification provider tend to add an orchestration layer in year two as the operations team grows.[4]







.png)