



Why Pure Cache or Pure Live-Ping Both Fail at Production Volume
A high-volume lending shop running 5,000 to 50,000 applications per month cannot treat every application identically. Pure-cache verification fails on freshness for newly-formed LLCs, name changes, and status transitions (covered in depth in our static SoS feeds analysis). Pure-live-ping verification fails on latency, cost, and state-source availability.
The cache-only failure mode
Cache-only architectures pull from a vendor database that was built from periodic bulk ingest of state registry data. Response time is sub-second. The cost is that the data is as fresh as the last refresh cycle, which ranges from daily on the fast end to monthly or quarterly on the low end.[1] For newly-formed businesses, recent name changes, and status transitions inside the vendor's propagation window, the cache returns either a false no-match or a stale-record match. Neither is a defensible input for an underwriting decision.
The live-ping-only failure mode
Live-ping architectures query the state registry at the moment of each API call. Most states return in 10 to 30 seconds. Delaware takes 15 to 30 seconds. Oregon can take up to 5 minutes.[2] Running live-ping as the primary verification on every application does three things wrong: it blocks synchronous onboarding UX, it burns per-call cost on the majority of cases where cache would have resolved cleanly, and it hammers state registries with traffic that creates rate-limit friction.
The industry response is the waterfall, and the design decisions inside the waterfall are where production reality diverges from the whiteboard.
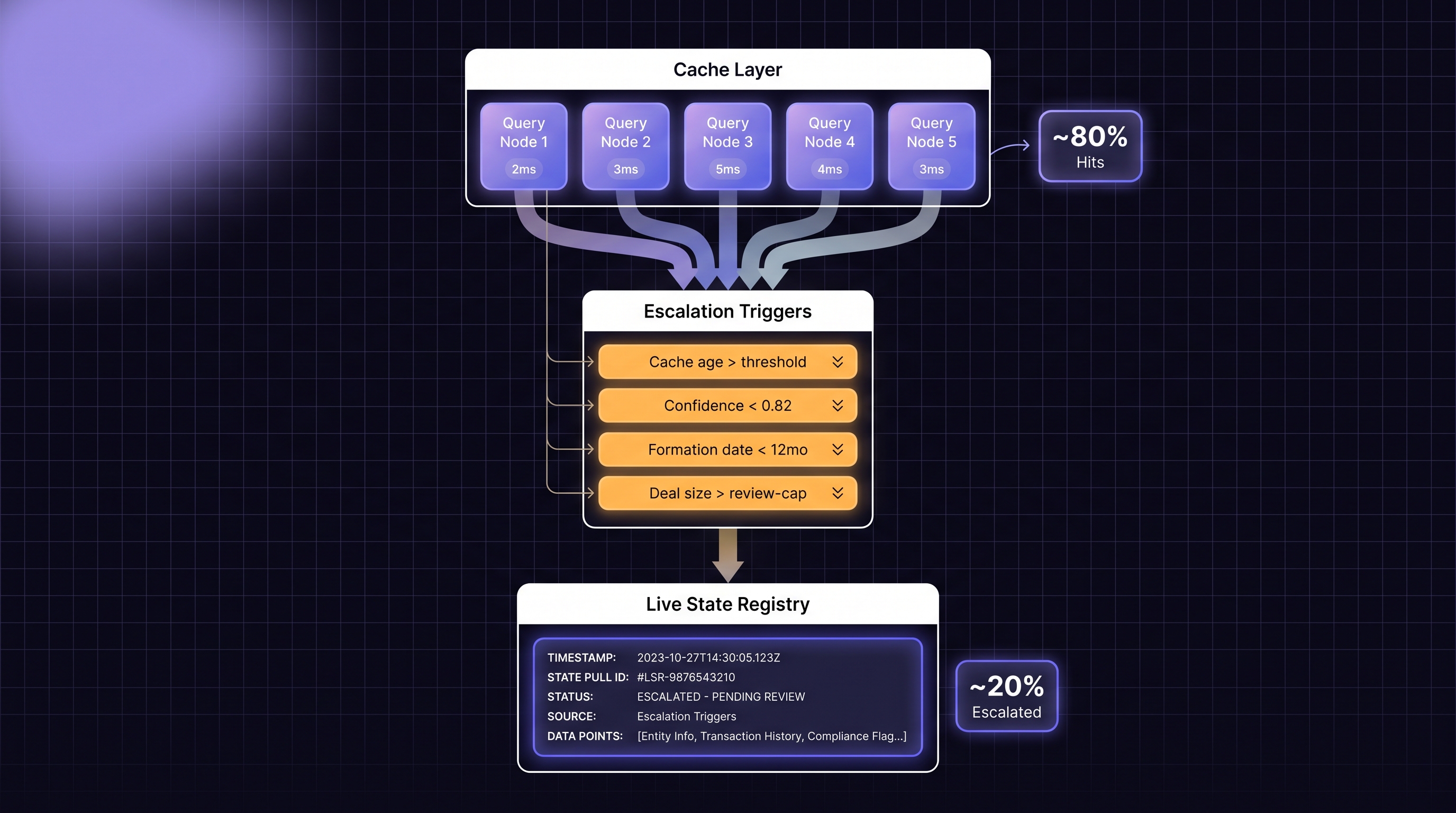
The Cache-First Real-Time-Fallback Pattern, Decomposed
The canonical pattern has four stages. Each stage has design decisions that affect throughput, cost, and audit-defensibility.
Stage 1: Cache lookup with freshness threshold
Query the cached data source first. Return immediately if the cache has a high-confidence match AND the cached record is fresh enough by your policy definition. "Fresh enough" is the critical parameter: formation date, last-update timestamp on the record, match confidence score, or a combination. A cached match on a 10-year-old stable business with confidence 0.95 is actionable. A cached match on a 3-month-old LLC with confidence 0.72 probably is not.
Stage 2: Escalation triggers
If stage 1 does not resolve, escalate. The escalation triggers are the policy surface of the waterfall. Common triggers:
• Cache no-match for any business.
• Cache match with confidence below your threshold (typical thresholds are 0.80 to 0.85 for auto-accept).
• Cache match but formation date within your freshness window (last 12 months is a common cutoff).
• Cache match but applicant reported a recent name or address change.
• Deal value above a threshold that demands registry-sourced evidence.
• Applicant is in a state known to lag (Delaware name-changes, Oregon status updates, New Jersey restricted data).
Each trigger routes to the live-ping layer. The trigger set is a policy choice, not a vendor choice; document it explicitly because examiners will ask.
Stage 3: Live-ping with async architecture
The live-ping call has to be structured async if the state-source response time exceeds your synchronous onboarding UX tolerance. Async-Request-Reply is the standard pattern: the client API call returns HTTP 202 with a status endpoint or sets up a webhook callback URL.[3] The state registry query runs in the background, and the result posts back via webhook when the state returns.
This is the structural reason most lenders who tried to wire live-ping synchronously into a same-session onboarding flow failed and reverted to cache-first. The architecture has to be async from the start for the slow-state tail (Oregon, Delaware) not to block everything else.
Stage 4: Result reconciliation and audit logging
When the live-ping result returns, reconcile it against the cache. If the live result contradicts the cache (live says active, cache said no-match), log both and treat the live result as authoritative. The reconciliation log is the examiner-facing audit artifact. It shows that the vendor cache was checked first, shows where it failed, shows what the live query returned, and shows the final decision.
Cache-First Waterfall: When to Use Which Path
Here is the rough decision matrix for routing each verification.
| Application Type | Cache-First Path Works | Trigger Live-Ping Fallback |
|---|---|---|
| Established business, stable history, low deal value | Yes, cache-only acceptable | If cache confidence drops below threshold |
| Business formed in last 12 months | No, cache too likely stale | Always trigger live-ping |
| Applicant reports recent name or address change | No, cache likely lagged | Always trigger live-ping |
| Delaware entity with reported name change | No, Delaware does not push name changes to feeds | Always trigger live-ping |
| High-dollar deal, any state | Cache plus live-ping for audit evidence | Always trigger live-ping for registry-sourced evidence |
| Portfolio re-verification, bulk | Cache-first, live-ping only on status-transition detection | Event-driven on exception |
| Perpetual KYB monitoring | Cache-first, scheduled live-ping re-verify | Interval-based per portfolio tier |
The matrix is directional. Each shop tunes the thresholds against its own state mix, deal-size distribution, and UX tolerance. The point is that "cache-first" and "live-ping fallback" are not mutually exclusive; they are the two ends of a routing policy that handles both.
When to Trigger the Live Fallback Automatically vs Manually
A common mistake in first-generation waterfall implementations is treating the escalation decision as a human-in-the-loop step. That works at 100 applications per day; it falls over at 5,000.
Automatic triggers
Automatic triggers should cover the cases where the rule is deterministic: freshness threshold breaches, confidence-score cutoffs, state-specific policy rules, deal-value thresholds. All of these can be expressed as API-layer routing logic. No human decides; the system decides based on published policy.
Manual triggers
Manual triggers should cover the cases where human judgment adds value: name-collision ambiguity where the live result shows multiple candidate matches, address mismatches that might be data-entry errors, officer-name mismatches that might be beneficial-owner structuring. These cases benefit from adjudication; automating them creates more operational risk than it saves.
The routing itself as a policy artifact
The line between automatic and manual is a policy decision the institution owns and an examiner will ask about. Document it. The documentation should specify: which triggers are automatic, which are manual, what the manual SLA is, who owns the queue, how decisions are logged. A waterfall without that policy documentation passes technical review and fails compliance review.
Handling the Slow-State Tail: Async Integration Inside the Waterfall
The slow-state tail is the architectural challenge that separates production-ready waterfalls from prototype ones.
Why async is not optional
Most states return live-ping results in 10 to 30 seconds. That is already too slow to block a same-session onboarding flow with a spinner. Delaware can take up to 30 seconds, which is worse. Oregon can take up to 5 minutes, which is catastrophic for synchronous UX. Async-request-reply, with HTTP 202 acknowledgment and webhook callback, is the only pattern that handles this without forcing a degraded user experience.[3] AWS and Azure architecture documentation both describe this pattern as the default for long-running operations.[4]
Webhook reliability in the financial-services stack
Webhook implementations in 2025 and 2026 have converged on a set of best practices: signed payloads for verification, exponential backoff on retry, idempotency keys, CloudEvents payload format for interoperability.[5] For verification pipelines specifically, signature verification on the callback is not optional: the webhook receiver is exposed on the open internet, and unverified callbacks open a denial-of-service surface.
The UX pattern
The synchronous user flow returns a "verification in progress" state while the async path runs. If the state response returns within a few seconds (most of the time), the UX can render the result immediately. If it takes longer, the user receives an email or in-app notification when the verification completes. Onboarding continues with partial verification state flagged until the async leg completes.
Idempotency, Retry Logic, and State Reconciliation
Three failure modes distinguish mature waterfalls from brittle ones.
Idempotency
Retry any stage of the waterfall safely: if the network fails mid-call, retry the same verification without creating duplicate records or double-charging the vendor API. Stripe and other payments APIs have made idempotency keys standard; the same pattern applies to verification APIs.[6] Send an idempotency key on every vendor call; the vendor returns the same result for a repeat with the same key.
Retry with exponential backoff
When a live-ping call fails transiently (state website down, vendor rate-limit, network error), retry with exponential backoff and jitter.[7] Jitter prevents thundering herd when multiple retries stack from a single upstream event. Cap retries at a reasonable number (typical: 3 to 5) and route to a circuit-breaker state for the specific state-source if failures persist.
Circuit breaker for state-source outages
When Oregon's state registry is down, every waiting verification will hit the same failure. A circuit breaker wraps the retry logic: if failures exceed a threshold in a time window, the circuit opens for a cooldown period, returning an explicit "state source unavailable" response rather than continuing to retry.[8] The institution's policy should define what to do with verifications that hit the open circuit: queue for later, decline, escalate to manual, or return a provisional result with explicit flagging.
What Breaks a Naive Waterfall at Scale
A waterfall that works in a dev environment can fall over in production for reasons that do not show up in unit tests.
Cache-poisoning via stale-record acceptance
If stage 1's freshness threshold is tuned too permissively, the waterfall accepts stale records and misses the escalation trigger. Result: the live-ping fallback never fires, and stale data flows through to underwriting. Symptom: false-negative complaints from operations. Fix: audit the cache-acceptance logs against actual state-registry truth on a periodic sample; tighten the threshold if drift appears.
Webhook loss
The async callback can be lost for several reasons: receiver downtime, firewall misconfiguration, signed-payload verification failure, expired callback URL. Loss rate is usually low but non-zero. Without monitoring, lost callbacks become orphaned verifications. Fix: track outbound live-ping calls with a correlation ID; reconcile against received callbacks on a scheduled sweep; surface un-reconciled verifications to an exception queue.
Vendor cache freshness claims that do not match vendor reality
Some vendors advertise "daily refresh" that turns out to be weekly in practice because the bulk-ingest pipeline has its own backlog. The waterfall's cache-freshness threshold is only as useful as the accuracy of the vendor's stated cadence. Fix: verify the freshness claim against sample businesses with known recent state-registry activity; adjust the freshness threshold based on observed reality, not vendor claims.
Policy drift between product, risk, and compliance
The escalation rules are often set by the risk team, implemented by engineering, and audited by compliance. As policies evolve (new state added to the lag list, threshold tuned after a fraud incident, new deal-value tier), the three teams drift out of sync. Fix: the policy lives in a single source of truth (configuration as code, ideally) with version history, and every change passes through all three teams.
Monitoring a Production Verification Waterfall
The monitoring layer is what converts a waterfall from a one-time architecture decision into a sustainable production system.
Metrics that matter
• Cache hit rate. Proportion of verifications resolved at stage 1. Falling hit rate = something is wrong (applicant pool shift, vendor cache degradation, threshold drift).
• Escalation rate by trigger. Which triggers are firing most? Helps identify where the policy is too tight or the cache is too weak.
• Live-ping latency distribution, per state. Delaware p50, Delaware p99, Oregon p50, Oregon p99. Drives capacity planning and SLA expectations.
• Callback reconciliation rate. Proportion of outbound live-ping calls that receive a matching callback within the expected window.
• Decision disagreement rate. Proportion of cases where cache and live-ping disagree. High disagreement = cache is stale in ways the freshness threshold does not catch.
• Circuit-breaker trip rate per state. How often each state-source outage fires the breaker. Drives vendor negotiation and contingency planning.
Alert thresholds
The metrics above are meaningless without alert thresholds calibrated to normal operation. A callback reconciliation rate of 92 percent might be fine for one shop and a crisis for another. Bake in a two-week baselining period after each deployment, then alert on deviations from that baseline rather than absolute thresholds.
The Waterfall Architecture Checklist
Before the next production release, run the waterfall against this checklist.
• Cache-layer freshness threshold documented and versioned as configuration-as-code.
• Escalation trigger set written as policy, mapped to code, reviewed by risk + engineering + compliance.
• Async path implemented with HTTP 202 acknowledgment, signed webhook callbacks, and correlation IDs.
• Idempotency keys on every vendor call.
• Retry with exponential backoff and jitter on transient failures, capped at a reasonable retry count.
• Circuit breaker per state-source with explicit open/half-open/closed states and cooldown policy.
• Callback reconciliation sweep scheduled to catch orphaned verifications.
• Policy drift controls preventing silent divergence between risk, engineering, and compliance views of the rules.
• Monitoring stack covering the six metrics above with baselined alerting.
• Audit log capturing for each verification: cache response, escalation trigger fired, live-ping correlation ID, callback timestamp, final decision.
Shops that pass this checklist operate waterfalls that scale. Shops that skip it operate waterfalls that look fine in the first three months and accumulate silent failure modes in month six.







.png)