



The Cost of an Ambiguous No-Match
Every lender running business verification has two kinds of no-match outcomes flowing through the exception queue: the no-match that reflects reality (the business is not registered) and the no-match that reflects vendor staleness (the business is registered but has not propagated into the feed). In most production systems, these two outcomes are indistinguishable at the API layer. The risk team treats them as the same signal, and that is where the cost enters.
The false-no-match problem, quantified
Sumsub, a competitor KYB vendor with a commercial interest in this framing, reported in its 2025 industry survey that 60 percent of verification providers name false positives and false negatives as one of the top three verification hurdles, alongside slow verification times and poor user experience.[1] Overall user pass rates reached 94 percent on average in 2025, up one point from 2024, which means that on the remaining six percent of verifications, the vendor either returned a false positive, a false negative, or a genuinely ambiguous result.[1] The survey methodology is self-interested, but the directional point is independently confirmable across the industry: at volume, false-negative ambiguity is a meaningful percentage of the pipeline.
A 10,000-verification-per-month shop running inside the directional 2-to-5-percent false-negative band that static feeds typically produce on newly-formed entities (an illustrative range reflecting published vendor surveys and architectural reasoning, not a measured field rate) is pushing 200 to 500 applications per month into manual review or decline on a signal the team cannot fully trust. Labor cost is the trivial part. The expensive part is that a meaningful share of those are legitimate businesses whose vendor feed has not caught up with the state registry, which translates directly into mispriced deals and adverse selection. Run your own vendor's documented refresh cadence and your own state-mix distribution to pin down where your actual rate lands; the directional point is that the rate is non-zero and does not surface in the normal operating dashboards.
Why examiners treat no-match documentation seriously
FinCEN and federal banking regulators have steadily raised the documentation bar for negative-outcome decisions. The IRS Bank Secrecy Act examination manual explicitly requires that "documentation is to be sufficient to allow an audit trail of the examiner's thought process and all significant findings."[2] The parallel expectation for the institution under examination is symmetric: your decision to decline, approve, or not file a SAR must be documented in a way that reconstructs the thinking at the moment of the decision.
FinCEN and the federal banking agencies issued interagency FAQs on January 19, 2021 and October 9, 2025 that specifically clarify documentation expectations for decisions not to file a SAR. The formal guidance states that "banks should document SAR decisions, including the specific reason for filing or not filing a SAR," and the same documentation logic applies to any decision built on a negative verification result.[3] A no-match that cannot be traced back to a state-registry query at a specific moment in time is a documentation gap waiting for an examiner finding.
What a True Negative Actually Is in Business Registry Verification
The term is borrowed from decision theory, where true positive, true negative, false positive, and false negative form a four-cell matrix describing the outcomes of any binary classifier. Business verification is a classifier: the vendor either matches the applicant to a real state-registry entity or it does not. Applied to KYB:
• True positive: vendor matches the applicant to the correct registry entity.
• True negative: vendor correctly reports no match, and the business truly is not in the registry at that moment.
• False positive: vendor matches the applicant to the wrong registry entity (a name-collision match).
• False negative: vendor reports no match for a business that is registered (staleness, propagation lag, name variations, or address mismatch).
The true negative is the category that is hardest to produce reliably, because it requires the vendor's database to accurately reflect the absence of a record in the source registry. That is only architecturally possible when the vendor queries the source registry at the moment of the API call. Any architecture that relies on bulk ingest and cache introduces a window in which the vendor's "no match" might just be vendor staleness.
The difference from decision theory and what lenders actually need
In academic decision theory, a classifier is evaluated against a ground-truth labeled dataset. In KYB verification, there is no ground-truth labeled dataset. The ground truth is the state registry itself, and the only way to know what the state currently shows is to ask it directly. Live-ping providers like Kyckr, Cobalt Intelligence, and Baselayer query the source at the moment of each API call.[4] Bulk-refresh providers (Middesk, many Alloy-default data integrations, legacy Dun and Bradstreet) query their own cache, which was built from a state registry snapshot that is some number of days or weeks old.
The practical consequence: a no-match from a live-ping provider is a snapshot of the registry at that moment and can be treated as a true negative with defensible confidence. A no-match from a bulk-refresh provider is a claim about the vendor's database, which may or may not reflect the registry's current state.
Why Most KYB Feeds Cannot Produce a Reliable True Negative
The architectural reasons track directly with the data-staleness problem covered in more depth in our static Secretary of State feeds analysis. A few that matter specifically for the no-match signal:
The propagation window is longest for exactly the no-match cases
State registries push updates to aggregators on cadences ranging from nightly to weekly to batch. The window between a formation filing and aggregator visibility routinely exceeds a week. For newly-formed entities, which represent the bulk of the false-negative population, that window is the difference between a defensible no-match and a data-lag artifact. Wolters Kluwer counted nearly 5.5 million new business formations across 47 states in 2025, most of them LLCs.[5] A meaningful share of any given day's applicant pool is inside that propagation window.
Name variations and normalization gaps look identical to no-match
Static feeds rely on the vendor's name-normalization logic to match "ACME Corporation" to "Acme Corp." to "A.C.M.E. Corp." to whatever the state registry happens to show. When normalization fails, the result is a no-match that looks identical to a legitimate absence. A live-ping provider can surface the alternatives list returned by the state registry itself, which exposes the variation directly and converts an ambiguous result into an actionable one.
Delaware, New Jersey, and the states that do not push changes to feeds
Delaware does not push business name-change updates into standard data feeds, which means that any Delaware entity whose legal name changed after the aggregator's last bulk ingest will return a no-match from a static feed. New Jersey restricts some status data by statute, requiring a paid per-request lookup at the state level. Oregon is slow across the board. The net effect is that state-level quirks compound inside the static-feed architecture, and the no-match signal becomes state-dependent in ways the vendor's API does not expose.
In practical audit terms, this means your examiner-facing documentation needs to account for the state distribution of your no-match outcomes explicitly. A portfolio weighted heavily toward Delaware LLCs (typical for most U.S. lenders because Delaware leads the country in LLC formations) carries materially higher false-negative ambiguity than a portfolio weighted toward Texas or California, which propagate filings into standard feeds faster. A risk policy that ignores this variance will produce audit files that look uniform on paper and uneven under scrutiny. The state-level architecture gets its own deep treatment in a separate post in this series on the Delaware name-change gap and equivalent state-by-state feed failures.
What Examiners Actually Want to See in Your No-Match Documentation
This is the part most verification stacks underinvest in, because it does not surface in the day-to-day underwriting UX. It surfaces during audit.
The documentation expectation, in concrete terms
Based on FinCEN, FFIEC, and IRS BSA examination manuals, an examiner reviewing a declined application on a no-match signal will expect to see, in the file:
• The timestamp of the verification query that produced the no-match.
• The specific state or states queried and the search parameters used.
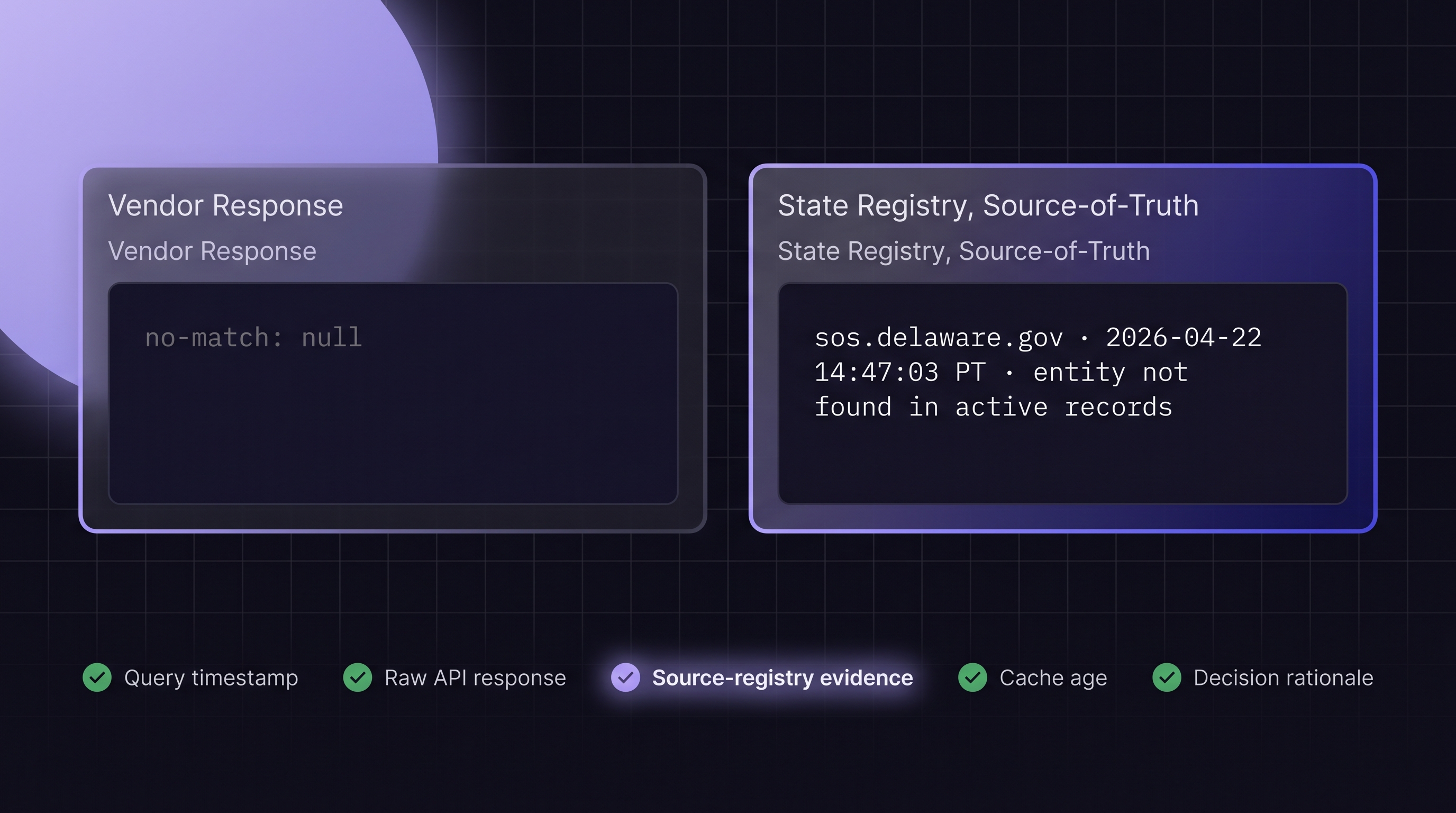
• The vendor's raw API response, not just a processed "no match" flag.
• Evidence of the source registry's state at the moment of the query (the timestamped screenshot is the gold standard here).
• Documentation of the decision logic that translated the no-match into a decline or escalation.
The 2021 and 2025 interagency FAQs on SAR filings establish the documentation bar for decisions not to file; the same bar applies by analogy to any negative decision in the KYB pipeline. If your file cannot reconstruct the thinking at the moment of the decline, that is an examiner finding.
Where the cache-layer no-match fails this test
When the verification comes from a cached vendor feed, the "evidence of source registry state" field is populated with the vendor's own database state, not the registry's. That is a weaker artifact. An examiner pressing on the question of why the vendor's database said what it said at the moment of the decision has no clean answer: the vendor's refresh cadence, the ingest pipeline, and the normalization logic all sit between the registry truth and the decision. A live-ping no-match with a timestamped state-registry screenshot answers the question in one step.
Building a Decline Policy Around Verifiable True Negatives
A decline policy that treats every no-match identically is treating a high-confidence signal and a low-confidence signal as equivalent. That is both operationally wasteful and audit-fragile.
A tiered policy structure
| No-Match Type | Underlying Signal | Policy Response | Documentation Requirement |
|---|---|---|---|
| Live-ping no-match with timestamped registry evidence | Registry shows no entity at moment of query | Treat as true negative; decline or escalate per risk framework | Full registry snapshot, query timestamp, API response |
| Live-ping no-match without timestamped evidence | Registry shows no entity but no audit artifact | Treat as true negative; capture evidence before declining | Secondary live query with screenshot |
| Cached no-match, vendor last refresh <24h | Vendor cache recent but still not source-current | Escalate to live-ping fallback before decline | Log cache age; trigger live query |
| Cached no-match, vendor last refresh >24h | Ambiguous; could be registry absence or propagation lag | Manual review or automatic live-ping retry | Log cache age, reason for escalation |
| Name-variation no-match | Vendor normalization failed; registry may have variant | Try alternative search strings; if live-ping, inspect alternatives list | Document variations tried |
The tiered structure accomplishes two things. It routes verifications to the fastest cost-efficient path when the cache is trustworthy, and it triggers the slower live-ping pathway for exactly the cases where the cached signal is ambiguous. It also creates a documentation artifact that an examiner can follow: the tier the decision was made at, and the evidence that supported that tier.
Where policy intersects with FinCEN's 30-day correction window, and where it does not
FinCEN's March 2025 interim final rule on beneficial ownership reporting actually removed BOI reporting requirements for U.S. companies and U.S. persons entirely. The revised rule applies only to foreign reporting companies that register to do business in a U.S. state or tribal jurisdiction, and those foreign entities must correct inaccurate information within 30 days of becoming aware of it.[6] For the portion of your applicant pool covered by that rule, a vendor whose cache refreshes monthly cannot reliably surface a correction inside the 30-day window by architecture.
The broader architectural point extends beyond the BOI rule specifically. Any portfolio-monitoring policy that depends on detecting state-level changes inside a defined window has the same dependency on verification freshness, whether the triggering deadline comes from BOI, state lender-licensing rules, warehouse-facility covenants, or internal credit policy. The window might be 30 days, 60 days, or 10 business days; the architectural question (can the vendor architecture surface the change inside the window that matters) is the same.
Combining Negative SoS Signals With Other Verification Layers
A no-match at the Secretary of State level is one input. A defensible decline rarely rests on one input. The higher-confidence pattern combines the negative SoS signal with other verification layers.
The SoS + TIN/EIN + OFAC stack
• SoS no-match + TIN/EIN mismatch: the business claims to be registered, but neither the state registry nor the IRS confirms the legal name. This is a high-confidence synthetic-identity signal.
• SoS no-match + OFAC negative: the business is not registered, and no sanctions match. The OFAC negative is ambiguous on its own (absence of a sanctions match does not prove legitimacy), but combined with a confirmed registry absence it supports a clean decline record.
• SoS no-match + court records negative: no registration plus no litigation history in covered jurisdictions. Again, the court-records negative is not load-bearing on its own, but the combination is.
Perpetual KYB and the shift from point-in-time to ongoing
Industry coverage in 2025 and 2026 has pushed hard on the concept of "perpetual KYB," in which verification shifts from a one-time onboarding check to a continuous re-verification process.[7] [8] The perpetual model makes the no-match signal more operationally important than the onboarding-only model does: a business that passed verification at onboarding may show a no-match signal six months later if it dissolved, was administratively struck off, or had its status revoked for non-payment of state fees. That mid-life signal needs to route against portfolio monitoring, not just application approval.
Where True Negatives Sit Inside a Perpetual KYB Program
If your KYB program runs continuously rather than at onboarding only, the no-match signal is no longer a one-time binary. It is a state change: the business was verified at time T1 and is showing no-match at time T2. That transition is meaningful and needs to be captured.
The state-transition audit log
A perpetual KYB program that captures state transitions has answers ready for examiner questions that a point-in-time program cannot answer. When the business dissolved, when the vendor detected the dissolution, how long the lag was between the two, what the institution did with the signal: all of these become queryable against the audit log. A bulk-refresh vendor contributes a state transition dated to its last refresh cycle, which is by definition lagged. A live-ping vendor contributes a state transition dated to the query timestamp, which is by definition current.
Risk-team workflow integration, with a concrete example
The risk team's workflow changes when the no-match becomes a continuous signal rather than a discrete one. Dissolution detection becomes a portfolio-level monitoring question rather than an onboarding one.
Concrete example. A customer is funded in January after passing onboarding verification. In April, the business files a voluntary dissolution with the state, and the state updates the entity status to Dissolved later that week. A perpetual KYB system configured against a live-ping data source detects the status change on its next scheduled re-verification (typically daily or weekly depending on portfolio tier), generates a portfolio-exception event in the risk system, and routes the account to a workout or collections review ahead of the next scheduled payment. The same detection against a monthly-refresh feed surfaces in May at the earliest, by which point the payment has already missed and the collection path has degraded materially. The architectural requirement is the same one the onboarding case surfaces: the vendor has to be capable of detecting the change inside the window that matters, and the audit log has to capture the detection timestamp so the policy can be reconstructed at exam time.
The No-Match Audit Checklist: What Every Risk File Should Contain
Before the next exam cycle, run every recent no-match decline through this checklist. Any gap is a finding waiting to happen.
• Query timestamp. The exact moment the verification query was issued, captured to the second.
• Query parameters. Business name, state, address, EIN, and any other fields submitted.
• Vendor API response. The raw response, not a processed label. The raw response allows the examiner to reconstruct what the vendor knew at the moment of the query.
• Source-registry evidence. A timestamped screenshot or equivalent artifact showing what the registry itself displayed at the moment of the query. This is the single strongest piece of documentation you can produce.
• Cache age, if applicable. If the no-match came from a cached source, the age of the cache entry at the moment of the query.
• Escalation path. What decision rule translated the no-match into a decline, a manual review, or an additional verification step.
• Final decision and rationale. The plain-language explanation of why this no-match resulted in this outcome, written in a way that an examiner can follow without reverse-engineering your policy document.
• Retention posture. Where the record lives, how long it is retained, how it is retrievable.
Files that pass this checklist survive audit cleanly. Files that miss any of these fields create examiner findings, and the remediation costs materially more than the incremental vendor spend required to produce the missing field in the first place.







.png)