



Why Binary Match Decisions Break at Volume
A verification layer that returns only "matched" or "not matched" forces every ambiguous case into manual review. At 500 applications per day, manual review scales. At 5,000 or 50,000, it does not.
The ambiguity problem
Real registry data contains ambiguity at the source. The applicant provides "ACME Corp" and the registry has "ACME Corporation" and "Acme Corp. Incorporated" and "Acme Industries, Inc." Which match is the applicant? A binary classifier picks one, gets it right most of the time, and gets it wrong enough of the time to matter. A confidence-scored classifier returns multiple candidates with scores and lets the underwriter or automated policy handle the disambiguation.
The threshold problem
Binary decisions hide a threshold. Somewhere in the classifier logic, "enough similarity counts as a match" is defined. That threshold is invisible to the consumer of the API. A threshold of 0.90 similarity produces different outcomes than a threshold of 0.75. Without surfacing the threshold, the consumer cannot tune it to their risk tolerance. Confidence scoring surfaces the underlying similarity directly.
The manual-review bottleneck
Manual review is expensive. The cost is not just the labor: it is the deal-flow delay. A 24-hour manual review cycle on an ambiguous case is a competitor approving the same applicant the day before your team gets to the queue. Confidence scoring lets the majority of cases route automatically (high-confidence matches auto-accept, very low-confidence no-matches auto-decline), reserving manual review for the narrow band where human judgment adds value.
How Confidence Scores Are Actually Produced
The underlying computation has several layers, and the layers matter for interpretation.
String similarity
The base layer compares the applicant-provided name against the registry name using string-similarity algorithms. Levenshtein distance, Jaro-Winkler, and similar algorithms produce a normalized similarity score between 0 and 1. Exact match returns 1.0; "ACME Corp" vs "Acme Corp" (case difference) returns something like 0.95; "ACME Industries" vs "Acme Corporation" returns something like 0.70.
Normalization preprocessing
Before string similarity runs, the input and the registry record pass through normalization: case-folding, trailing-punctuation removal, abbreviation expansion (LLC, Corp, Inc, L.L.C., Ltd, etc.), and stop-word removal ("The," "Of"). Normalization is where vendor implementations diverge; two vendors running the same underlying string-similarity algorithm can produce different confidence scores because their normalization rules differ.
Contextual weighting
Beyond name similarity, the confidence score typically incorporates additional signals: address match, state match, entity-type match, officer-name match where available. The weighting between these signals is a vendor policy choice. A verification where the name matches strongly but the address is wrong should score lower than one where both match. A verification where the name partially matches but the officer name matches perfectly is an interesting intermediate case.
AI-assisted matching and the explainability constraint
AI-assisted matching covers a range of approaches: LLM-based disambiguation of candidate entities, embedding-based similarity (captures semantic relationships beyond string edit distance), and ML models trained on historical match-quality labels. The architectural claim across these approaches is the same: combine string similarity with semantic and contextual signals to produce a more accurate confidence score than pure string comparison.
The practical question for a regulated lender is not which AI technique to use but whether the resulting score is defensible in audit. Compliance teams and examiners will ask: why did this applicant score 0.72? A useful confidence-scored verification response exposes the component signals (name similarity 0.85, address match true, officer match false, state match true) alongside the composite score. Without that decomposition, the score is a black box and not defensible.
Where AI-assisted matching breaks
The common failure mode is hallucinated matches. An LLM asked to disambiguate candidates can produce a confident ranking of entities that do not exist in the registry, or assign high confidence to a match a human would not. The fix is to constrain the AI layer to selecting only from the registry's actual candidate list, and to require the composite score to include the underlying string-similarity component so hallucinated signal does not inflate the final score. Pure string similarity is trivially explainable; embedding-based similarity requires documenting the vector space; LLM-based disambiguation requires documenting the model and prompt. Each additional layer adds capability at the cost of explainability. For regulated decisioning, explainability is not optional; the vendor's AI-assisted scoring has to expose enough structure that the consumer can reconstruct each decision in audit.
Confidence Score Thresholds: A Defensible Policy Structure
The confidence-scored decisioning policy is a set of thresholds that route each verification to an action.
A three-tier structure
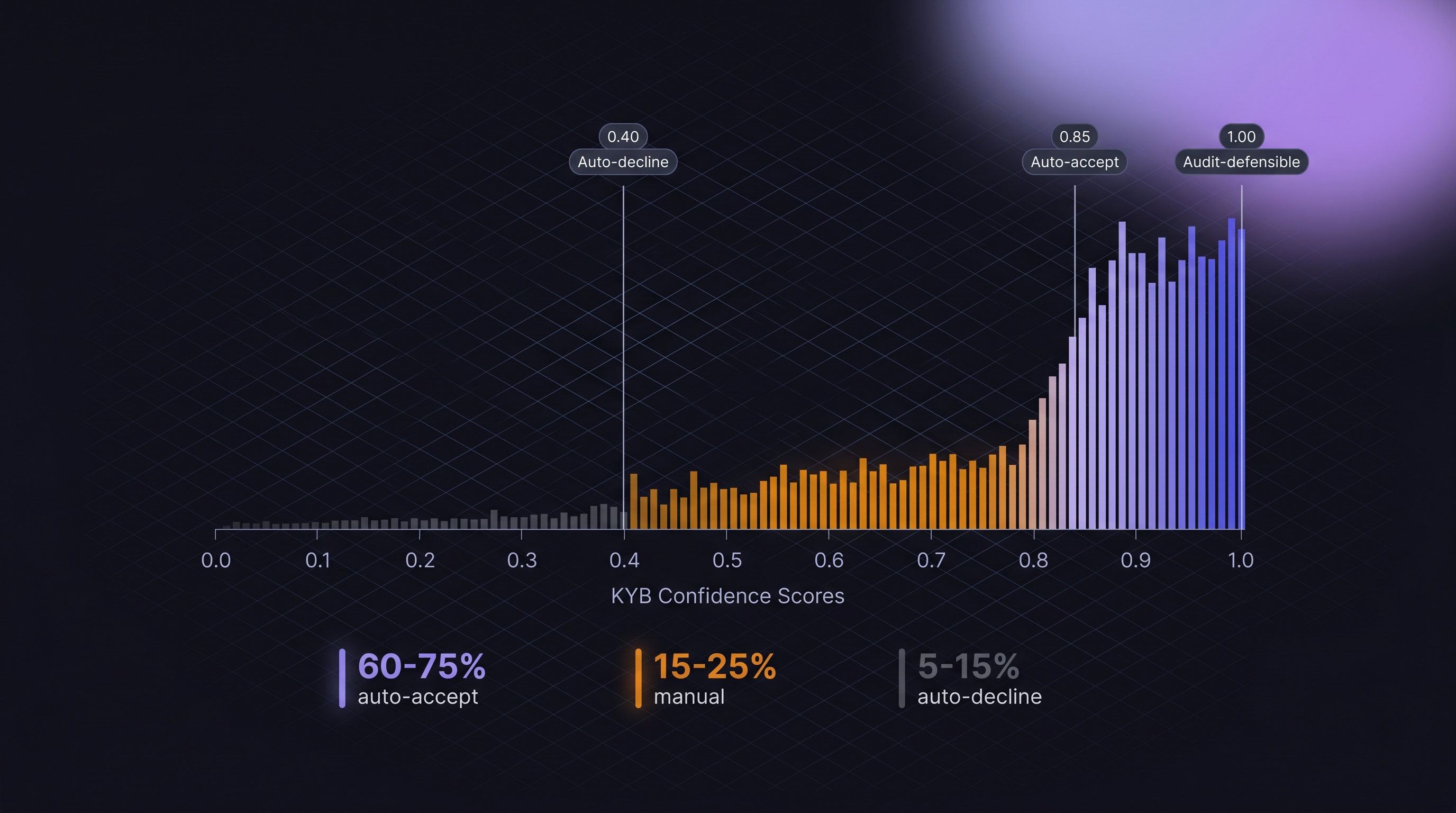
• Auto-accept band (typical: 0.85+ or 0.90+): Match is high enough confidence to proceed without human review. The applicant proceeds to the next onboarding step.
• Manual-review band (typical: 0.60-0.85): Match quality is plausible but ambiguous. The verification routes to a human reviewer with the candidate list and confidence breakdown.
• Auto-decline band (typical: below 0.40 or 0.50): No plausible match. The verification fails; the applicant sees a decline or is routed to an alternative verification path (document upload, manual data entry correction).
Where thresholds should be tuned
The right thresholds depend on the shop's risk tolerance, manual-review capacity, and applicant-pool characteristics. A high-volume MCA shop with limited manual review capacity might set auto-accept at 0.85 and auto-decline at 0.50, leaving a narrow manual band. A more conservative lender with higher-dollar deals might set auto-accept at 0.92 and accept a wider manual band to preserve accuracy.
The periodic-tuning requirement
Thresholds are not set-and-forget. Over time, the distribution of confidence scores in your applicant pool can shift (state-mix changes, applicant-demographic changes, vendor-scoring-model updates). Schedule a quarterly tuning review: sample cases from each tier, verify outcomes, adjust thresholds based on observed false-positive and false-negative rates.
The decline-threshold asymmetry
Setting the auto-decline threshold too aggressively declines legitimate applicants who had a name typo or an address mismatch. Setting it too permissively pushes fraud into the manual band where it may get through. The asymmetry matters: false auto-accepts are more expensive in fraud losses than false auto-declines are in lost deal flow, but both are real costs. Tune the two thresholds together, not independently.
Tiered Routing: What Happens at Each Confidence Level
Here is the operational routing pattern for a defensible confidence-scored policy.
| Confidence Band | Typical Range | Routing | Documentation |
|---|---|---|---|
| High confidence match | 0.90 - 1.00 | Auto-accept | Store confidence score, component signals, vendor response |
| Standard match | 0.80 - 0.90 | Auto-accept with flag | Store components; sample for periodic review |
| Borderline match | 0.65 - 0.80 | Manual review | Reviewer sees candidate list, component breakdown, reason for ambiguity |
| Weak match | 0.50 - 0.65 | Manual review with elevated scrutiny | Reviewer applies additional checks (document verification, EIN match) |
| No plausible match | 0.40 - 0.50 | Auto-route to alternative verification | Applicant sees "we need additional information" prompt |
| Clear no-match | 0.00 - 0.40 | Auto-decline | Store decline reason and confidence for audit |
The bands are illustrative; the specific ranges depend on the shop's tuning.
Common Failure Modes in Production Confidence Scoring
Three patterns account for most confidence-scoring bugs in production KYB integrations.
Drift in vendor-side scoring
The vendor updates its scoring model. Cases that previously scored 0.82 now score 0.78. Your auto-accept threshold at 0.80 now routes cases to manual review that used to auto-accept. Symptom: manual-review queue grows without an apparent applicant-pool change. Fix: version the scoring model in the vendor response, alert on version changes, re-run your threshold tuning.
Normalization boundary cases
Applicant enters "ACME Corp." with trailing period. Registry has "ACME Corp" without. Vendor's normalization drops trailing punctuation before string similarity. Confidence score is 0.99 (nearly exact match). Another applicant enters "ACME LLC" and registry has "ACME Inc." Vendor's normalization expands LLC and Inc. to their full forms. Confidence score is 0.45 (looks like different entities because different suffixes). Two cases that feel similar to a human produce very different scores; the normalization layer is the reason.
The same-name-different-entity problem
"Smith Consulting LLC" might exist in 20 states, each a different entity. A name-only search can return 20 candidates at similar confidence. Without state and address disambiguation, the confidence score on any single candidate is misleading (it is high on name but undifferentiated on entity identity). Fix: require state match as a precondition for high confidence; decay confidence when multiple same-name candidates exist without stronger disambiguators.
Officer-name normalization inconsistency
Officer name "John F. Kennedy" in the application versus "John Kennedy" in the registry. Pure string similarity on "John F. Kennedy" vs "John Kennedy" is not 1.0. A normalized comparison (strip middle initials, then compare) produces 1.0. The vendor's name-normalization logic for officers should match the logic used for entity names; mismatched logic produces inconsistent scoring across the same verification.
The Confidence-Scored Decisioning Checklist
Before the next policy review, run your confidence-scoring setup against this checklist.
Operational benchmarks to calibrate against. A healthy confidence-scored pipeline at production volume typically sees roughly 60 to 75 percent of verifications resolve in the high-confidence auto-accept band, 15 to 25 percent in the manual-review band, and 5 to 15 percent in the auto-decline band. These are directional ranges, not SLA-grade figures; the distribution shifts based on applicant-pool mix, state concentration, and vendor-side scoring logic. Measure your own over a representative month. A manual-review band above roughly 30 percent is a signal that thresholds are miscalibrated, vendor normalization is leaking information, or the applicant pool has shifted in a way the policy has not caught. A manual-review band below roughly 10 percent on a newly-deployed policy is a signal that thresholds are set too permissively and fraud risk is leaking into auto-accept.
Process items.
• Confidence score as primary routing field in the verification response schema.
• Component signal breakdown (name similarity, address match, state match, officer match, entity-type match) alongside composite score.
• Vendor-scoring-model version captured in the response.
• Tier thresholds documented (auto-accept, manual review, auto-decline) with explicit rationale plus the observed distribution that justifies each threshold.
• Quarterly threshold tuning scheduled with sampling plan against the benchmarks above.
• Alert on model-version changes that could shift the score distribution, and on unexpected movement in tier distributions.
• Explainability layer that produces a human-readable rationale for each decision.
• Same-name disambiguation that decays confidence when multiple candidates exist without stronger state or officer match.
• Normalization parity between entity-name and officer-name logic.
The shops that pass this checklist operate confidence-scored pipelines that survive compliance review. The shops that skip it rely on binary match decisions and pay for it in manual-review scale and fraud exposure.







.png)