



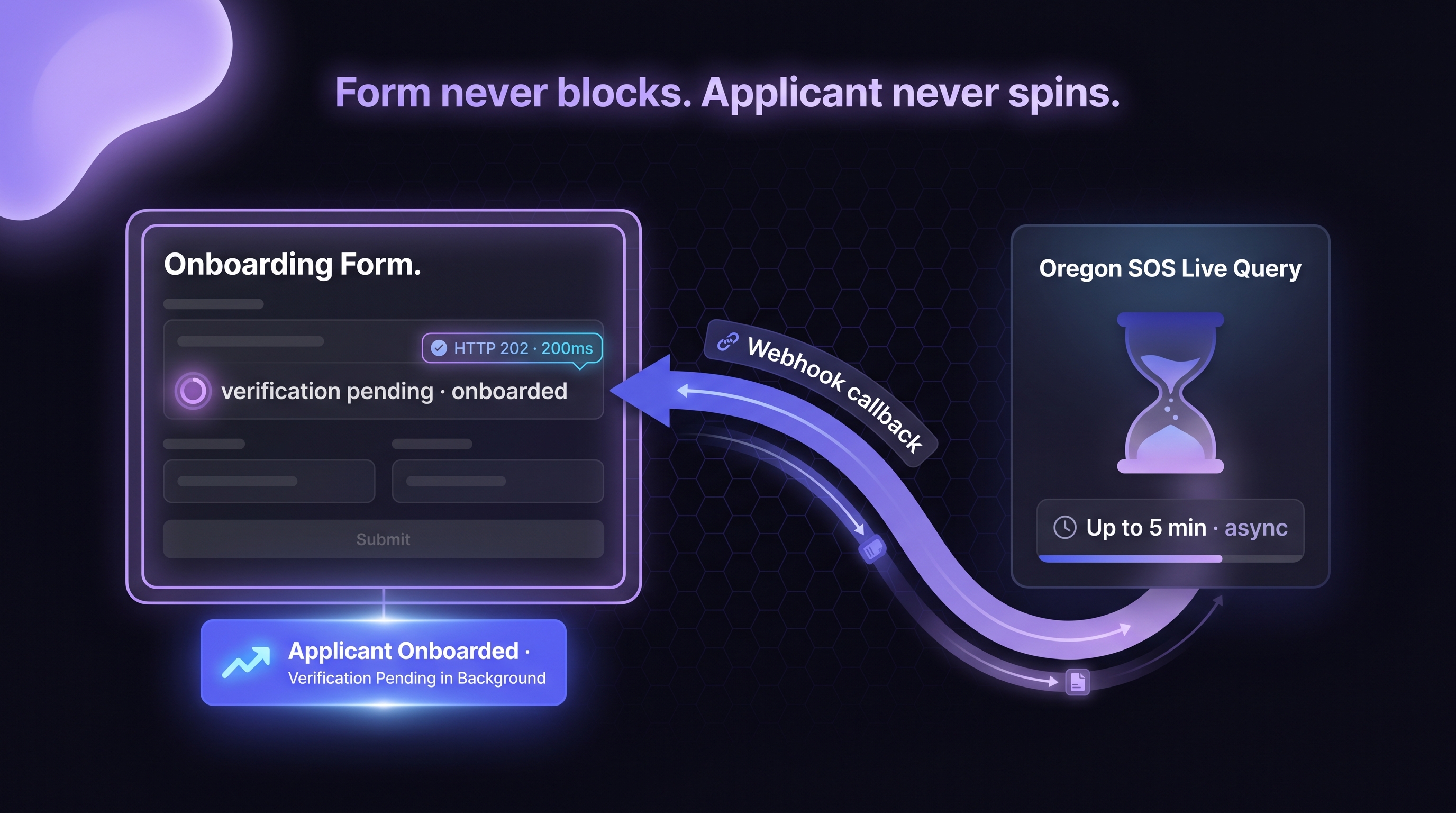
Why Synchronous Integration Fails at State-Response Latency
The naive integration is a straight-line synchronous call: client calls verification API, API calls state registry, state returns, API returns to client, client proceeds. This fails for reasons that compound at volume.
HTTP timeout ceilings
Most web frameworks and load balancers cap synchronous HTTP request duration at 30 to 60 seconds. State-response latency that exceeds the cap fails with a timeout even when the state would eventually have returned successfully. Oregon's 5-minute tail guarantees timeout on a synchronous path regardless of how the rest of the stack is configured.
User experience degradation
A user filling out an onboarding form and waiting 30 seconds for verification to complete is a user who abandons. At scale, the abandonment rate is measurable in deal-flow loss. Progressive-disclosure UX requires that the synchronous path returns quickly enough to keep the user engaged; anything above 3 to 5 seconds is already degraded.
Connection pool exhaustion
At production volume, synchronous long-running calls tie up HTTP connections. A shop running 1,000 concurrent onboarding sessions with 60-second synchronous verification calls holds 1,000 open connections for 60 seconds each. Connection pools, load balancer capacity, and downstream infrastructure all buckle under that pressure. The same workload on async architecture holds connections only for the initial request-acknowledgment roundtrip (milliseconds) and reconnects asynchronously when the callback fires.
Retry-storm amplification
When a state source returns slowly or intermittently, synchronous retries compound the pressure. Client retries on its timeout. API retries on its timeout. State responds to the original query while the retries stack. The result is duplicate queries, rate-limit triggering, and in some cases a temporary DOS of the state registry. Async architecture with idempotency keys prevents the storm by deduplicating on the vendor side.
The Async Request-Reply Pattern, Decomposed
The canonical pattern, documented in Microsoft Azure Architecture Center and AWS Architecture documentation, has three stages and a callback.[1] [2]
Stage 1: Client submits verification request with callback URL
The client POSTs the verification parameters along with a callback URL the vendor should notify when the verification completes.
curl --location 'https://apigateway.cobaltintelligence.com/v1/search' \
--header 'x-api-key: YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"searchQuery": "Acme Industries LLC",
"state": "oregon",
"liveData": true,
"callbackUrl": "https://yourapp.example.com/webhooks/cobalt-verification",
"idempotencyKey": "app_20260422_123456_oregon"
}'Stage 2: Vendor acknowledges with HTTP 202 and correlation ID
The vendor returns HTTP 202 Accepted with a correlation ID the client can use to look up the verification status or reconcile against the future callback.
{
"status": "accepted",
"statusCode": 202,
"requestId": "abc123-def456-ghi789",
"retryId": "retry_abc123",
"message": "Verification queued. Results will post to callbackUrl.",
"estimatedCompletionSeconds": 180
}Stage 3: Vendor queries state registry asynchronously
Inside the vendor infrastructure, the verification request routes to the state-registry query layer. This layer handles the slow-state tail: Oregon's 5-minute latency, Delaware's 15-30 second response, California's high-volume queue. The client is not holding a connection during any of this.
Stage 4: Vendor POSTs callback when state returns
When the state registry returns, the vendor POSTs the result to the callback URL with a signed payload.
{
"requestId": "abc123-def456-ghi789",
"status": "complete",
"statusCode": 200,
"idempotencyKey": "app_20260422_123456_oregon",
"results": [
{
"title": "ACME INDUSTRIES LLC",
"status": "Active",
"normalizedStatus": "Active",
"stateOfFormation": "Oregon",
"filingDate": "2024-03-15",
"registeredAgent": {
"name": "Registered Agent Services Inc",
"address": "123 Main St, Portland, OR 97201"
},
"sosUrl": "https://sos.oregon.gov/...",
"screenshotUrl": "https://screenshots.example.com/..."
}
],
"callbackSignature": "sha256=abc123..."
}Stage 5: Client verifies signature and processes result
The client verifies the callback signature, looks up the correlation ID, matches against the pending verification, and proceeds with the underwriting decision. The synchronous onboarding flow has already completed with a "verification pending" state; the async path now completes the verification in the background.
Callback URL Security: Signing, Verification, and Replay Protection
Webhook callbacks are exposed on the open internet. Without security controls, the endpoint is a denial-of-service surface and, worse, a trust surface an attacker can exploit.
HMAC signing
The standard pattern is HMAC-SHA256 signing: the vendor computes a signature over the payload using a shared secret, the client verifies the signature before processing.[3]
# Client-side verification (pseudocode)
received_signature = headers['X-Cobalt-Signature']
computed_signature = hmac_sha256(secret, request_body)
if not constant_time_compare(received_signature, computed_signature):
reject(401)Constant-time comparison prevents timing-attack leakage of the secret.
Timestamp validation
Include a timestamp in the signed payload and reject callbacks older than a reasonable window (5 minutes is typical). This prevents replay attacks where an attacker captures a legitimate callback and re-sends it later.
Ephemeral signing keys
Rotate signing keys regularly. Industry 2025-2026 pattern is ephemeral signing keys scoped per endpoint or per tenant, which limits the blast radius if a key is compromised.[3] Support key rotation without downtime by accepting both the current and previous key during a grace window.
Source-IP allowlisting
Restrict callback-endpoint access to the vendor's documented outbound IP ranges. This is not a primary control (IP spoofing is non-trivial but possible), but it is a reasonable defense-in-depth layer.
Reconciliation: What to Do When the Callback Never Arrives
Callbacks can be lost. The reconciliation path is the difference between a reliable pipeline and a lossy one.
Known loss modes
• Callback endpoint downtime. Your endpoint was down when the vendor tried to POST.
• Signature verification failure. Signing key mismatch, clock skew, payload tampering (real or suspected), bug in your verification code.
• Network-layer loss. DNS failure, connection timeout, packet loss.
• Vendor-side failure. The vendor's callback dispatcher failed to send.
• URL invalidation. Your callback URL changed without updating the vendor configuration.
The correlation-ID sweep pattern
On every outbound verification request, record the correlation ID (`requestId` in the examples above) with a timestamp. Schedule a reconciliation sweep (hourly is typical) that:
1. Queries outstanding verifications older than the expected completion window.
2. For each, calls the vendor's retry-ID endpoint to retrieve the result.
3. Matches the result against the stored pending verification.
4. Either completes the verification or flags it to an exception queue.
# Retry-ID lookup pattern
curl --location 'https://apigateway.cobaltintelligence.com/v1/search' \
--header 'x-api-key: YOUR_API_KEY' \
--data-urlencode 'retryId=retry_abc123'The dead-letter queue
Verifications that cannot be reconciled after several sweep cycles move to a dead-letter queue. The queue is the examiner-facing artifact: these verifications were attempted, the state response was not retrievable, and the institution made an explicit policy decision (decline, escalate, retry manually). A pipeline without a dead-letter queue loses verifications silently, which is an audit finding waiting to happen.
Monitoring the reconciliation rate
Track the proportion of outbound verifications that complete via callback versus via reconciliation sweep versus via dead-letter. Healthy pipelines show callback completion rates above 95 percent with single-digit sweep-reconciliation rates. Shifts in this ratio are signals: rising sweep rate means callbacks are being lost; rising dead-letter rate means the state source itself is degrading.
Handling the Slow-State Tail: Oregon and Similar
Oregon is the canonical slow-state example. Designing for Oregon by default handles most other slow-state cases.
Per-state SLA expectations
The pipeline should have per-state latency SLAs documented, not a single global SLA. Oregon p99 of 5 minutes is qualitatively different from Texas p99 of 30 seconds, and lumping them into a single SLA produces either over-provisioning for Texas or under-service for Oregon.
Per-state circuit breakers
When a state source is completely down, the circuit breaker trips for that state without affecting verifications for other states.[4] Oregon being down should not prevent California verifications from completing. Implement the circuit breaker at the state-routing layer, not at the global API layer.
UX accommodation
The onboarding UX should know which state the applicant is in and adjust expectations accordingly. An Oregon applicant might see a longer "verification in progress" message; a Texas applicant expects near-immediate completion. The UX copy and the email-notification logic both benefit from per-state awareness.
Idempotency in the Async Path
Idempotency keys prevent duplicate processing when callbacks are retried.[5]
Client-generated idempotency key
The client generates a unique key (typically correlated to the underlying application ID) and passes it on every vendor API call related to the same verification. The vendor stores the key on first receipt and returns the same response for subsequent calls with the same key.
Callback idempotency
On the callback side, the client stores the received `requestId` and deduplicates. A callback received twice (common with retries) should not cause the verification to complete twice, should not double-fire any downstream triggers, and should not log duplicate entries in the audit trail.
The exactly-once-effective pattern
True exactly-once delivery is a distributed-systems unicorn. The practical pattern is at-least-once delivery plus idempotent processing, which is exactly-once-effective. The callback can be sent multiple times; the client processes it exactly once regardless.
Retry Strategy for the Async Layer
Retries happen at multiple layers: vendor retries callback delivery, client retries callback processing, both retry the underlying state-source query if it failed.
Exponential backoff with jitter
The default pattern is exponential backoff: retry after 1 second, then 2, then 4, then 8, with jitter added to prevent synchronized retry storms across the fleet.[5] Cap the total retry duration; verifications that have not completed after the cap move to dead-letter.
Retry-only-on-transient-errors
Retry on network errors, 5xx responses, and explicit rate-limit responses. Do not retry on 4xx validation errors, authentication failures, or explicit "permanently failed" responses. The retry logic should inspect the error type and make the decision.
Circuit-breaker integration
Retries should run inside circuit breakers, not around them. If the circuit is open for a state source, retries for that state source should not fire; they should fail fast to the dead-letter queue. This prevents amplifying load against a source that is already unhealthy.
Monitoring an Async Verification Pipeline
The metrics that matter for async pipelines differ from synchronous ones.
• Request acceptance latency. Time from client POST to HTTP 202 response. Should be <500ms.
• Callback delivery latency p50 and p99. Time from HTTP 202 to callback received, per state.
• Callback success rate. Proportion of outbound requests that complete via direct callback (vs reconciliation sweep vs dead-letter).
• Signature verification failure rate. Proportion of callbacks that fail signature check. Should be near zero; non-zero indicates key mismatch, clock skew, or attack attempt.
• Dead-letter queue depth. Number of verifications that could not be reconciled after retry cap. Should trend toward zero over time; a growing queue is a signal.
• State-source circuit-breaker trip count. Per state, per time window. Rising trip count is an early warning on a degrading state source.
• Idempotency-key hit rate. Proportion of requests that match an existing key and return a cached response. High rate indicates aggressive retry behavior upstream.
The Async Architecture Checklist
Before the next production release, run the async verification pipeline against this checklist.
• HTTP 202 acknowledgment path with correlation ID return.
• Idempotency keys on every vendor call.
• Callback endpoint with HMAC signature verification, timestamp validation, replay protection.
• Key rotation policy with grace-window support.
• Source-IP allowlisting as defense-in-depth.
• Correlation-ID sweep reconciliation scheduled at a sensible cadence.
• Dead-letter queue for verifications beyond retry cap.
• Per-state SLAs and circuit breakers with independent thresholds.
• Exponential backoff with jitter on retries, capped at a reasonable total duration.
• Retry-only-on-transient-errors logic with explicit error-type checks.
• Monitoring stack covering the seven metrics above.
• Runbook for the most common failure modes (callback loss, circuit-breaker trip, key rotation, vendor-side outage).
The shops that pass this checklist operate async pipelines that scale. The shops that skip it operate pipelines that look fine in staging and accumulate silent failure modes in production.







.png)